By Peter Debney
For the last few years I have been giving a lecture at Leeds University on design optimisation techniques, but the one thing that always bothered me was a sketch that I did of an example design space. This sketch was just that, a simple block diagram indicating what I assumed it would look like. When I had the opportunity to write the lecture up for a paper in The Structural Engineer, I realised that the time had come to do it properly.
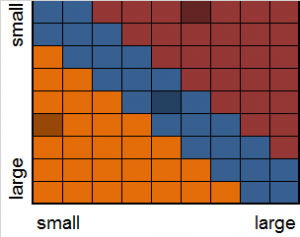
First, some background: what is it that we mean by a Design Space? It is essentially a very useful way to think about the design options, and can consider things like steel or concrete, flat slab or beam and slab, column spacing, etc. down to what beam sizes to choose. It is sometimes also called the Search Space or Phase Space. If we consider each option type is a dimension then the result is a plane (2 options), a cube (3 options), or a hypercube (4 or more options) where all the possibilities exist. The trick is to find where our economical yet functional design sits in this space.
For this example I wanted a structure that had just two dimensions of choice, so that I could draw it, yet also exhibited interesting or complex behaviour. I chose two beams of equal length joined to each other mid span, with a central point load. Obviously one design result is that the two beams are the same size and they carry the load equally. The other is that one beam does all the work while its partner just gives restraint.
The design principle was simple too: analyse the beams, determine the moments, and choose the lightest or cheapest beam that can carry the load. In design space terms, we start from one location (the two analysed beam sizes) and jump to another (the two sections from the design). You might refer to this as a quasi-Newton heuristic, if you were so inclined.
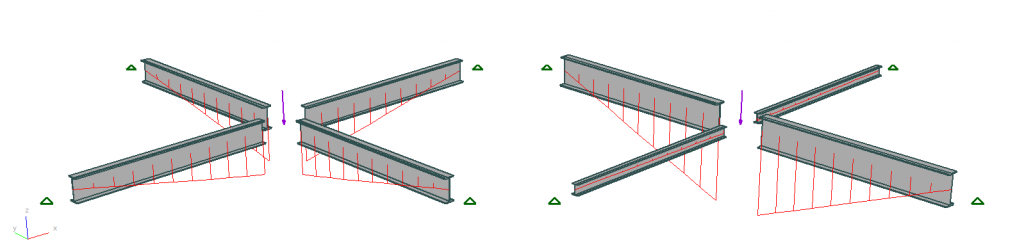
Two solutions
The problem with this this method on this structure is one of moment interaction. The moments are proportional to the beams’ relative stiffnesses, with the stiffer beam attracting more moment. When we design the beams, the stiffer beam can thus increase in size more than the lighter one, attracting more moment, and so on. The result is that it can take several steps to converge on a stable answer (the analysed sections are the same ones found in the design).
There are nearly 100 universal beam sections in the UK catalogue, giving us close on 10,000 possible locations in the design space for this simple structure. Normally we might just make a good guess at the initial sizes and take it from there, but for this exercise I wanted to map every point of the design space.
To do all 10,000 calculations by hand would be tedious, even if we halved it by taking the problem’s symmetry into account. Instead I wrote a Python script to work with the model, testing each option and outputting the results to a spreadsheet-friendly csv file.
As this script was to work with a single model I could afford to take some shortcuts. For example as I know that there are only two members then I don’t need the script to either count them or check for their existence when looping through the list. Neither do I need to read the design properties so that I can update them; instead I can hard code the design values into the script. Also, if this script was actually optimizing the structure we would get it to update the analysed sections with the ones found by the design, then repeat until no sections changed. So instead of a quasi-Newton optimisation we will get a map of how the quasi-Newton method would traverse the space.
In this model I placed all the section sizes I wanted to check, placing them into weight order. Price order was another option, combining TATA’s published price modifiers with the current base price. By doing this, then always working upwards through the list during the design check, we will either get the lightest or cheapest section that can carry the load.
The first version of this script works through all the possible pairs of beams, then determines the new pair that will carry the moment. In this instance I first reduced the section list by removing any section that has a lower moment capacity (effective length 5 m) than a lighter section. This reduced the section list down to a third, and thus the design space by a factor of nine to just over 1,000. Apart from greatly speeding up the investigation, it should also remove any sections that would not be chosen anyway: a double advantage. It is almost always worth the effort to remove the options that cannot be chosen, and the advantage grows with the dimensions of the design space. With two beams the reduction was to (1/3)2, with three beams (1/3)3, and so on.
Looking at the results we can see that if the initial sections are the same then the resulting beams will also be, as we would expect. If the sections are reasonably light then the self-weight does not play a significant part in the moment and we jump straight to the final answer. If we start at the heavy end then it can take a couple of iterations to converge.

Deviating a little from this symmetry takes us to a nearly symmetrical solution, which I did not expect. Make the starting point a little more uneven and we diverge off to the extremes, where one beam does all the work. Because the ratio of stiffnesses is changing so radically, it can take over half a dozen steps to converge. An especially interesting aspect is that the quasi-Newton method would not actually converge in this instance, as we get an oscillation between two sections for the restraining beam. A robust optimisation routine will have to watch out for this and fix on the one option that can carry the load.
The next stage was to investigate the question of design fitness. Fitness, or how close the answer is to the ideal, or how much better is an answer is compared to another, is a key metric in a number of optimisation routines, such as genetic algorithms and particle swarms. The problem is how can we define the fitness of a structural design solution? Weight or cost needs to be one aspect, but the lightest beams are no good if they cannot carry the load. Thus we also need to take capacity or utilisation into account. Also, because a beam that is not quite strong enough can be the gateway to one that it, we cannot simply exclude all beams that fail, but we should penalise them. Thus a beam at 95% utilisation is clearly better than one at 105%, but how do we compare one just over at 105% to an inefficient one at 5%? In this example I chose to measure the fitness as the unity factor if it is equal or below 1.0, and one over twice the unity factor if it is over.
Once we have the fitness of every beam pair we can then use them to contour the design space. If we take just the reduced section selection from above then we get a reasonable ridge that includes the results found by the quasi-Newton method.
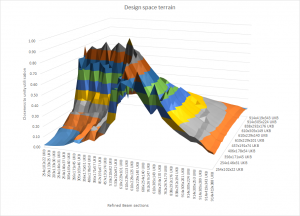
Optimised design space terrain
On the other hand if we take all the 96 UB sections then the picture is not quite so clear. We still get a ridge but the terrain is considerably rougher. If we were using a gradient method then we might struggle to get all the way to the highest peak.
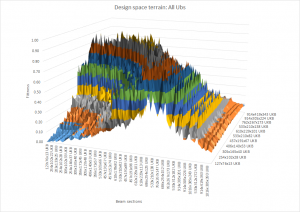
Unoptimised design space terrain
My Python 3.5 code is included below, plus the original GSA file. Please feel free to improve it and don’t forget to change the directory path to match your own!
## GSA Steel Design ##
import win32com.client
import pythoncom
import csv
# functions
def util(n): # calculate how close the section design is to unity
if n > 1:
result = 1 / (2*n) # penalise beams that fail
else:
result = n
return result
# variables - edit the directory to suit !
directory = "C:\\Users\\peter.debney\\Documents\\Visual Studio projects\\PythonSteelDesign\\"
model = "Cruciform.gwb" # GSA file
sect_min = 1 # number of first section profile
sect_max = 32 # number of last section profile
# open GSA model
gsa_obj = win32com.client.Dispatch("Gsa_8_7.ComAuto") # early binding
gsa_obj.Open(directory + model)
# create output file
with open('results.csv', 'w', newline = '') as csv_data:
output_file = csv.writer(csv_data)
for i in range(sect_min, sect_max + 1): # loop through steel beams
row_array = [] # create empty row array
for j in range(sect_min, sect_max + 1): # loop through steel beams
# set new member sections
MembText1 = ("MEMB 1 NO_RGB MT_STEEL MB_BEAM " + str(i) +
" 1 1 1 4 2 0.000000 0 0.000000 NO_RLS NO_OFFSET ")
gsa_obj.GwaCommand(MembText1)
MembText2 = ("MEMB 2 NO_RGB MT_STEEL MB_BEAM " + str(j) +
" 1 1 1 5 3 0.000000 0 0.000000 NO_RLS NO_OFFSET ")
gsa_obj.GwaCommand(MembText2)
gsa_obj.Delete("RESULTS") # delete analysis results
gsa_obj.Tool_UpdateElemSections() # set element sections to match members
gsa_obj.Analyse() # run analysis
for ii in range(sect_min, sect_max + 1): # find section for member 1
MembText1 = ("MEMB 1 NO_RGB MT_STEEL MB_BEAM " + str(ii) +
" 1 1 1 4 2 0.000000 0 0.000000 NO_RLS NO_OFFSET ")
gsa_obj.GwaCommand(MembText1)
# design check - OP_INIT_1D_AUTO_PTS = 0x20 (32) calculate 1D results at interesting points
iStat = gsa_obj.Output_Init(0x20, "default", "A1", 14006001, 0)
if gsa_obj.Output_Extract(1, 0) < 1: # stop when suitable section found
break
for jj in range(sect_min, sect_max + 1): # find section for member 2
MembText1 = ("MEMB 2 NO_RGB MT_STEEL MB_BEAM " + str(jj) +
" 1 1 1 5 3 0.000000 0 0.000000 NO_RLS NO_OFFSET ")
gsa_obj.GwaCommand(MembText1)
# design check - OP_INIT_1D_AUTO_PTS = 0x20 (32) calculate 1D results at interesting points
iStat = gsa_obj.Output_Init(0x20, "default", "A1", 14006001, 0)
if gsa_obj.Output_Extract(2, 0) < 1: # stop when suitable section found
break
# output the resulting member sizes
row_array.append(str(ii) + " + " + str(jj))
## calculate average efficiency of structure and add to the results array
#row_array.append((util(gsa_obj.Output_Extract(1, 0)) + util(gsa_obj.Output_Extract(2, 0))) / 2)
output_file.writerow(row_array) # add results array to output csv file
Errata
Following on from conversations with various readers concerning changing the above code to work with Python 2.7, substituting the following line to open the CSV results file seems to work:
# create output file
with open('results.csv', 'w') as csv_data:
output_file = csv.writer(csv_data, lineterminator='\n')